See also: Six and a half intuitions for kl divergence.
The cross entropy is defined as the expected surprise when drawing from , which we’re modeling as . Our map is while is the territory.
Now it should be intuitively clear that because an imperfect model will (on average) surprise us more than the perfect model .
To measure unnecessary surprise from approximating by we define
This is KL-divergence! The average additional surprise from our map approximating the territory.
Now it’s time for an exercise, in the following figure is the Gaussian that minimizes or , can you tell which is which?
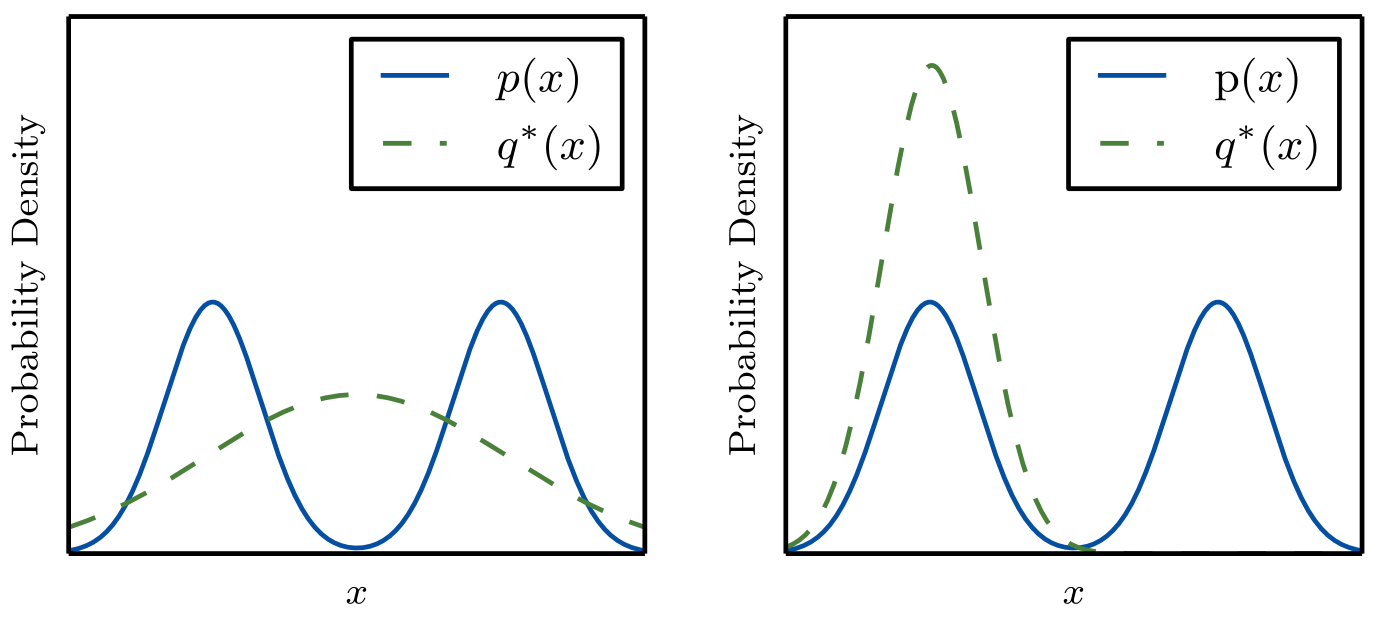
Answer
Left is minimizing while the right is minimizing .
Reason as follows:
- If is the territory then the left is a better map (of ) than the right .
- If is the map, then the territory on the right leads to us being less surprised than the territory on the left, because on the on left will be very surprised at data in the middle, despite it being likely according to the territory .
On the left we fit the map to the territory, on the right we fit the territory to the map.