
Prerequisites
- Know what an integral represents
- Know about taylor series for approximating functions
- Sufficient mathematical maturity
Introduction
If you’re confused see Notation, if that doesn’t clear it up contact me so I can fix the post to be more understandable.
Demo
This polynomial
Is the best fifth degree polynomial approximation for over (within roundoff of course).
Do you see the two graphs? They’re so close it’s hard to tell there are two! If you compute the squared error (where denotes our polynomial approximation)
We find it’s a really good approximation for , taylor polynomials don’t even compare with an error of .
The best part? These optimal polynomial approximations can be efficiently found for any function, in fact, for complicated functions they’re easier to find then taylor series!
Here’s the code if you want to play with it before learning the math
Done? Okay, then get ready for…
Linear Algebra
Though a bit of an exaggeration, it can be said that a mathematical problem can be solved only if it can be reduced to a calculation in linear algebra. Thomas Garrity
Before you truely understand the demo we’ve got to learn some linear algebra! To be specific you need to know
- Vectors and vector spaces
- Subspaces
- Bases
- Inner products and orthogonality
- Orthonormal bases
- Orthogonalization
I won’t be covering linear transformations (the heart of linear algebra) at all, because they aren’t needed here.
Important: Attempt the exercises and read the solutions. I’ve put a lot of content in the solutions so skipping them will make reading this impossible.
The standard space
Before we get to polynomials, let’s consider “vanilla” linear algebra, where every vector a list of numbers in .
Adding and scaling vectors works as you’d expect
In abstract linear algebra vectors are any object you can add and scale like this.
Exercise: Functions and Polynomials are also vectors, convince yourself of this
Solution
We can add functions and multiply by scalars and the result will still be a function, same with polynomials
The set vectors are contained in is called a vector space. A vector space has a few requirements
- Closed under addition: If and then
- Closed under scaling: If and then
Without these properties working in a vector space would be impossible, imagine adding two vectors and not knowing if the result is also in the space!
Exercise: Why must the zero vector be in every vector space?
Solution
Set and use (2).
Exercise: Show the space of polynomials of degree exactly is not a vector space
Solution
It doesn’t contain the zero polynomial.
Exercise: Fix the problem shown in the previous exercise to get us a vector space of polynomials
Solution
Consider the space of polynomials with degree at most (denoted ). This satisfies the vector space rules since
- Adding polynomials of degree at most results in polynomials with degree at most , so we’re closed under addition
- Scaling polynomials can only decrease their degree, so we’re closed under scaling
Subspaces
A vector space is said to be a subspace of if is contained in , ie. .
Exercise: Show the space of polynomials (of any degree) is a subspace of all real functions (denoted )
Solution
The set of polynomials is a vector space, and every polynomial is also a function, in set notation . Hence is a subspace of .
Exercise: Interpret our original problem of finding th degree polynomial approximations as a special case of: given a find the closest to (often called the projection of onto )
Solution
Consider (the space of functions continuous on ) and . then and we want the closest th degree polynomial to .
The dot product
To compute the dot product between two vectors in (lists of numbers) we multiply components then add up, ie.
As a special case the dot product of a vector with itself gives the length squared
The dot product has a very satisfying geometric interpretation: If is the angle between and then
Geometrically this means the dot product is the length of projecting onto the line through then scaling by (or the other way around). See this video for why.
Exercise: Convince yourself that and when denotes the dot product.
Exercise: Using the projection interpretation, what is the projection of onto the line through ?
Solution
First normalize by dividing by it’s length, then take the dot product and scale in the direction of , which we normalize again to avoid unwanted scaling
This is usually written as (after using linearity of )
Exercise: Expand in terms of dot products, then use the geometric interpretation to prove the law of cosines.
Solution
Expand using linearity just like you would with polynomials!
Using the geometric interpretation this becomes
Which is the law of cosines!
Exercise: Compute the area of the parallelogram formed between and using dot products
Solution
Consider this diagram
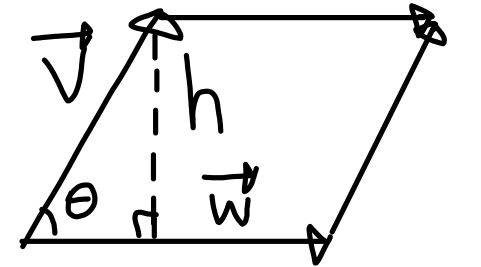
The height is meaning the area is . Writing this in terms of dot products we get
Exercise (optional): Using the result from the previous exercise, derive the formula for the determinant of a 2x2 matrix (if you know what this means)
Solution
Suppose we have the matrix
Consider the basis vectors as and . Then the area between them is the determinant (watch these if that doesn’t make sense) meaning
General inner products
Like vectors, there can be many kinds of inner products, for instance on the space of continuous functions on we can define an inner product
Intuitively this is the continuous version of the dot product, where we treat functions as infinite-dimensional vectors.
Like we abstracted the notion of a “vector” we also abstract the notion of an inner product to be anything that obeys a set of rules
- Positivity
- Definiteness if and only if
- Symmetry
- Additive
- Multiplicative
Exercise: Convince yourself that both inner products I’ve given so far satisfy these properties.
To generalize length we define the norm of a vector as
Exercise: Generalize the law of cosines to any inner product .
Solution
Exactly the same steps as with the law of cosines
If we were in we could use the geometric interpretation to write like we did for the law of cosines.
Exercise: In the geometric interpretation we showed the dot product can be used to compute the cosine of the angle between two vectors, ponder the infinite-dimensional analog of this in function space (the cosine similarity of two functions!)
Solution
With dot products we had
Since the integral inner product is just a limit of dot products as the vectors get bigger and the samples become finer, it makes sense to define the cosine similarity between functions this way. We could also extract the angle using the inverse cosine if we felt like it, and talk about the angle between functions!
Exercise (hard): Why do we need and to be continuous and not just integrable? (hint: think about property 2)
Solution
The function
Is integrable on with , but breaking requirement 2.
Showing this can’t happen with continuous functions is tricky, but it boils down to implying there’s a neighborhood around with meaning it contributes nonzero area.
Orthogonality
We say two vectors and are orthogonal if
Exercise: Prove the pythagorean theorem for an arbitrary inner product, ie. prove that implies .
Solution
We expand using the linearity of inner products and cancel the term
Exercise: If is the dot product and are nonzero vectors, show and are orthogonal if and only if they are perpendicular (hint: use the geometric interpretation)
Solution
To see this directly notice the projection is zero exactly when are perpendicular. (see this video)
We can also use the geometric formula
Because are nonzero we have and meaning this is only zero when , which only happens when is a multiple of degrees, ie. when and are perpendicular.
Bases
A basis for a vector space is a list such that
- Spanning: Every can be written for some scalars .
- Independent: The representation of as a combination of is unique.
Exercise: Convince yourself and form a basis for
Exercise: Show and form a basis of
Solution
Every can be written
Hence is spanning, to show independence note that
Implies (via rearrangement)
Since the first coordinates must equal this implies , this implies the left hand side is zero meaning we must have as well, implying . Thus and and we have shown independence.
We say a basis is orthogonal if when . And we say a basis is orthonormal if it’s orthogonal and (ie. the basis vectors have unit length).
Orthogonalization
Given a basis of it’s possible to construct an orthonormal basis of .
Start by setting so . now we want in terms of such that .
We want this to be zero, so we subtract the projection of onto (see the geometrically interpretation for why I call it a projection)
Exercise: Verify using linearity (hint: is just a number)
Solution
I left out the step where we normalize , but understand after we make it orthogonal we normalize it too, in programming terms .
In general we subtract the projection onto each of the previous basis vectors
Exercise: Show (hint: without loss of generality assume )
Solution
Using the definition of and orthogonality gives
The key difference from the exercise above is using the orthogonality to cancel the other terms in the sum.
Exercise: Translate the mathematical algorithm I’ve described into python code using numpy and test it
Solution
import numpy as np
def normalize(v):
return v / np.sqrt(np.inner(v,v))
v = [np.array(vi) for vi in [(1,4,2), (3,2,1), (5,1,2)]]
e = [normalize(v[0])]
for i in range(1, len(v)):
e.append(normalize(
v[i] - sum(
np.inner(v[i], e[j])*e[j]
for j in range(i)
)
))
# test it
for i in range(len(v)):
for j in range(i):
assert np.allclose(np.inner(e[i], e[j]), 0)
This method is called the Gram–Schmidt process.
Least squares
We finally get to solve the approximation problem! We have a vector space , a subspace and some vector . We want to find the closest vector to in (ie. the projection).
I’ve you’ve been following along and doing the exercises you’re close to understanding the method, the main ideas are:
- We can write where is an orthonormal basis of , and is an orthonormal basis of .
- We can extract using inner products and orthogonality, meaning we can extract the component of in giving us the projection.
Exercise: Find a simple formula for in terms of and
Solution
Since orthogonality kills off every other term in
The above exercise allows us to define the projection of as
Exercise (optional): Prove is a linear map (if you know what that means)
Solution
Via substituion and linearity of we see
The case is the same.
Furthermore since and the matrix of in the basis is the identity (for the ) followed by zeros (for the ‘s)
Notice , we extracted component of using inner products and orthogonality!
Now, intuitively it makes sense for to be the closest vector to , and in the intuition is correct. But for arbitrary vector spaces we need a more general argument.
Consider the remainder (error) vector , the key fact: the remainder is orthogonal to
Exercise: Show for all (hint: use ‘s basis and linearity of )
Solution
Let and let be such that
Meaning
Now we expand the part of
Now from the definition of and orthogonality we see meaning
Applying this for gives as desired.
Because of this, any tweak to can only move us away from ! We can prove this using the generalized pythagorean theorem since and are orthogonal.
This has a minimum at , meaning we can’t do better!
Polynomial approximation
We’ve covered all the linear algebra we need! It’s time to walk through approximating over with a fifth degree polynomial.
Here’s a simplified version of the code, which you should be able to understand!
import sympy as sp
x = sp.Symbol('x')
# function we're approximating
def f(x):
return sp.sin(x)
a,b = -sp.pi, sp.pi
def inner(f, g):
return sp.integrate(f*g, (x, a, b))
def normalize(v):
return v / sp.sqrt(inner(v, v))
# basis of U (polynomials up to degree 5)
B = [1,x,x**2,x**3,x**4,x**5]
# orthogonalize B
O = [normalize(B[0])]
for i in range(1, len(B)):
O.append(normalize(
B[i] - sum(
inner(B[i], O[j])*O[j] # <v_i, e_j>
for j in range(0, i)
)
))
# get coefficients
coeffs = [inner(f(x), O[j]) for j in range(len(O))]
# turn the coefficients into a sympy polynomial
poly = sum(O[j]*coeffs[j] for j in range(len(coeffs)))
# print the polynomial as latex!
print(sp.latex(poly))
# print the polynomial in numeric form
print(sp.latex(poly.evalf()))
# => 0.00564312 x^{5} - 0.1552714 x^{3} + 0.9878622 xFull code (with more features) is here. Have fun playing with it!
If you don’t understand, tell me! I’ll be happy to explain, I want this to be understandable to everyone.
Notation
We denote vectors in a vector space by , If we’re dealing with a subspace , then denotes a vector .
Scalars (real numbers) are denoted by or . often when taking linear combinations we have a list of scalars .
We denote the inner product between and as . The specific inner product is clear from context. In other sources the dot product is written or , these notations are specific to the dot product and don’t extend to general inner products.